Article
Classifying text with AWS Textract
Feb. 4, 2021
What is AWS Textract?
AWS Textract is an AWS service that allows the user to extract text and data from scanned documents such as insurance forms, loan applications, bank forms or survey questions. Amazon Textract automatically reads and extracts text from the documents and organizes the data into raw text, forms and tables. Enabling the data to either be reviewed by processes downstream or ingested directly into an application or database.

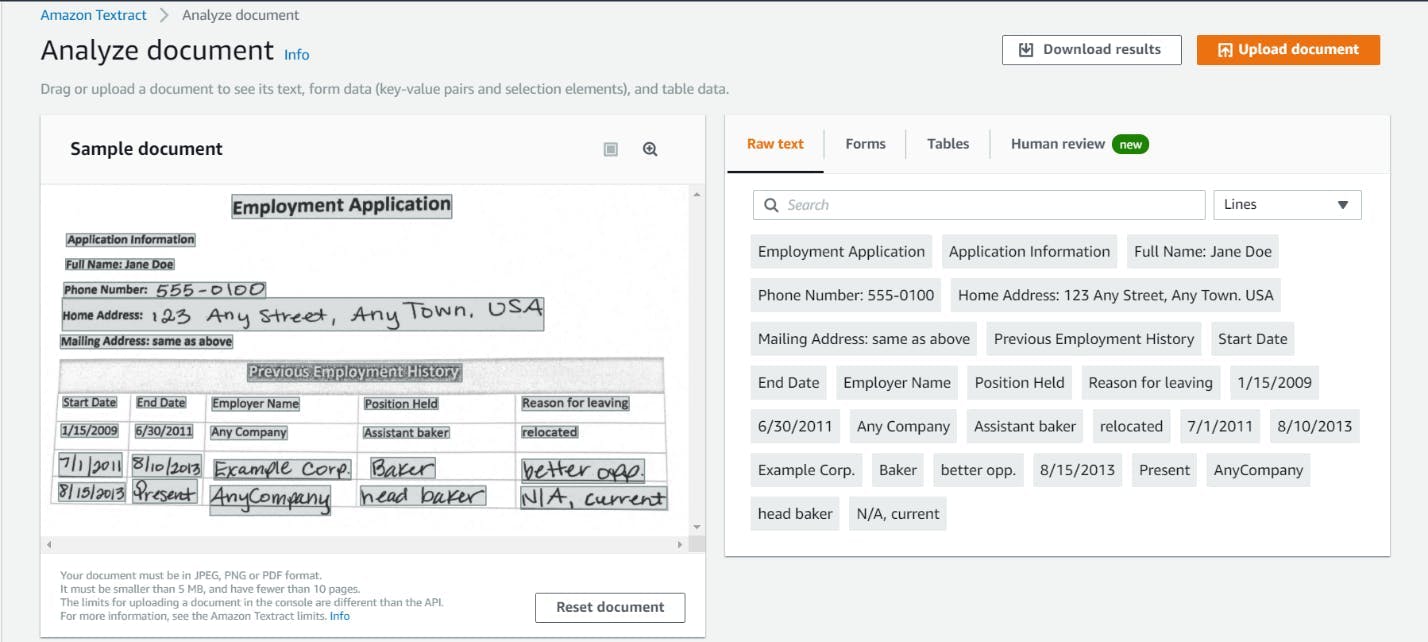
Figure 1: This image describes the business problem that AWS Textract solves
History of the Optical Character Recognition
Let us take a step back and briefly discuss what optical character recognition (OCR) is so that we can understand the impact of AWS Textract. Starting in the late 1800s through the early 1900s, the earliest concepts of OCR were developed to help the blind read. WWII and into the Cold War, OCR tools were used to convert Morse code to text. As time and technology progressed, OCR was used to digitize coupons and postal addresses. OCR’s capabilities grew exponentially with the microprocessor, resulting in additional capabilities such as price tag scanners, passport scanners and the ability to scan historically handwritten textbooks for preservation purposes. Currently, OCR is used in nearly every industry including automatic cameras that read your license plate when you speed through a red light, scanning a check with your phone to deposit it in real time, or even Google Translate when you are in a foreign country and in need of a quick translation of a menu or a sign!
How does OCR work?
Suppose we read a brand-new book. Think about how our eyes differentiate the background from the actual text. We identify the shapes of each letter and each word to form sentences as long as they are legible. We recognize the words and sentences on pages regardless of the print type, such as cursive, block, print or italicized, or font. Our brains are designed to recognize characters. Computers, however, need to be instructed on how to read in the same manner. Think of the letter “A”. Each of us think slightly differently about how the letter “A” is formed, but all versions are acceptable. A computer needs to understand that each one of those forms is equivalent to the letter “A” based on the pixel orientation within a word, sentence and document.
Article Tags